
Longitudinal data is very exciting as it enables us to look at change in time, get a better understanding of causal relationships and explain events and their timing. To make use of this type of data typically we need to move beyond classical statistical methods, such as OLS regression and ANOVA, to models that can deal with the extra complexity of the data.
One popular model for analyzing longitudinal data is the Latent Growth Model (LGM). This enables the estimation of change in time while taking into account the hierarchical nature of the data (multiple points in times nested within individuals). It is similar to the multilevel model of change but it is estimated using the Structural Equation Modeling (SEM) framework and uses data in the wide format (each row is an individual and measurement in time appears as different columns).
More precisely the LGM can help:
- understand how change happens in time
- explain change using time-varying and time-constant predictors
- decompose variance in between and within variation
- can be easily extended (e.g., mixture LGM, second order LGM, parallel LGM)
Here I’m going to give a brief intro to LGM, how to estimate it and how to visualize change estimates.
First, let’s load the packages. We will use tidyverse for cleaning and visualization of the data and lavaan for running the LGM in R.
library(tidyverse) library(lavaan)
Before we get into LGM let’s have a look at the kind of data we would want to analyze. Here I use the log income from the first six waves of the Understanding Society survey which can be downloaded form the UK Data Service. This is a large representative panel of the general population in the UK collected every year.
Let’s imagine we are interested in how income changes in time. More precisely, we want to see how income changes on average as well as separating between variation, how people change compared to others, and within variation, how people vary relative to their own average/trend.
First, let’s see how the data looks like. Let’s look at the wide data, this is the data used to run LGM:
head(usw) ## # A tibble: 6 x 7 ## pidp logincome_1 logincome_2 logincome_3 logincome_4 logincome_5 logincome_6 ## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 7.07 7.20 7.21 7.16 7.11 7.21 ## 2 2 7.15 7.10 7.15 6.86 7.00 7.26 ## 3 3 6.83 6.93 7.57 7.27 7.58 6.97 ## 4 4 7.49 7.63 7.52 7.46 7.62 7.65 ## 5 5 8.35 5.57 7.78 7.73 7.75 7.77 ## 6 6 7.80 7.82 7.89 6.16 4.61 6.91
Next, let’s look at the long format where each row is a combination of individual and time. This is the format we need for visualization using ggplot2 and for other models (like the multilevel model for change).
head(usl) ## # A tibble: 6 x 3 ## pidp wave logincome ## <fct> <dbl> <dbl> ## 1 1 1 7.07 ## 2 1 2 7.20 ## 3 1 3 7.21 ## 4 1 4 7.16 ## 5 1 5 7.11 ## 6 1 6 7.21
To get an understanding of what we will be modelling let’s make a simple graph showing the average change in time as well as the trend for each individual.
ggplot(usl, aes(wave, logincome, group = pidp)) +
geom_line(alpha = 0.01) + # add individual line with transparency
stat_summary( # add average line
aes(group = 1),
fun = mean,
geom = "line",
size = 1.5,
color = "red"
) +
theme_bw() + # nice theme
labs(x = "Wave", y = "Logincome") # nice labels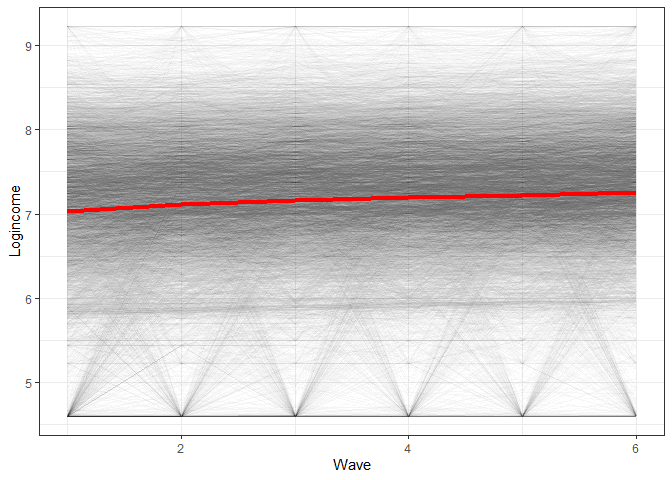
So we see we have an average change in time that we want to estimate but also quite a lot of variation in the way people change. LGM is able to estimate both at the same time!
What is Latent Growth Modelling?
So now that we have an idea about the data and the kind of research questions we might have we can move to the LGM. The formula for the LGM is actually very similar to the one for the multilevel model of change:
yj = α0 + α1λj + ζ00 + ζ11λj + ϵj
Where:
- yj is the variable of interest (logincome for us) that change in time, j.
- α0 represents the average value at the start of the data collection (the starting point of the red line above).
- α1λj is the average rate of change in time (the slope of the red line in the graph above). Here λj just represents a measure of time.
- ζ00 is the between variation at the start of the data. Summarises how different are the individual starting points compared to the average starting point.
- ζ11λj is the between variation in the rate of change. Summarizing how different are the individual slopes of change compared to the average change (red line above).
- ϵj is the within variation or how much individuals vary around their predicted trend.
We can get a better idea of the different sources of variation in the graph below:
usl %>% filter(pidp %in% 1:2) %>% # select just two individuals ggplot(aes(wave, logincome, color = pidp)) + geom_point() + # points for observer logincome geom_smooth(method = lm, se = FALSE) + # linear line theme_bw() + # nice theme labs(x = "Wave", y = "Logincome") # nice labels
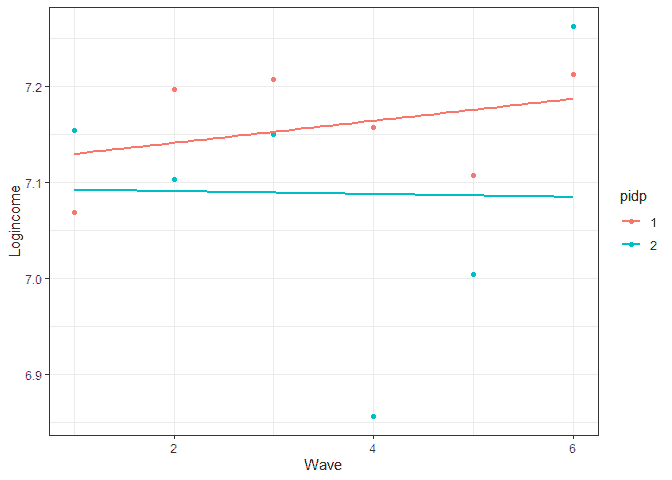
The within variation is represented by the distance between the line and the points. This is done separately for each individual (by colour in the graph). The between variation refers to how different are the lines. This could be either the starting point or the slope.
Structural Equation Modeling has its own way of representing these statistical relationships. Here is how we would represent the model described above:
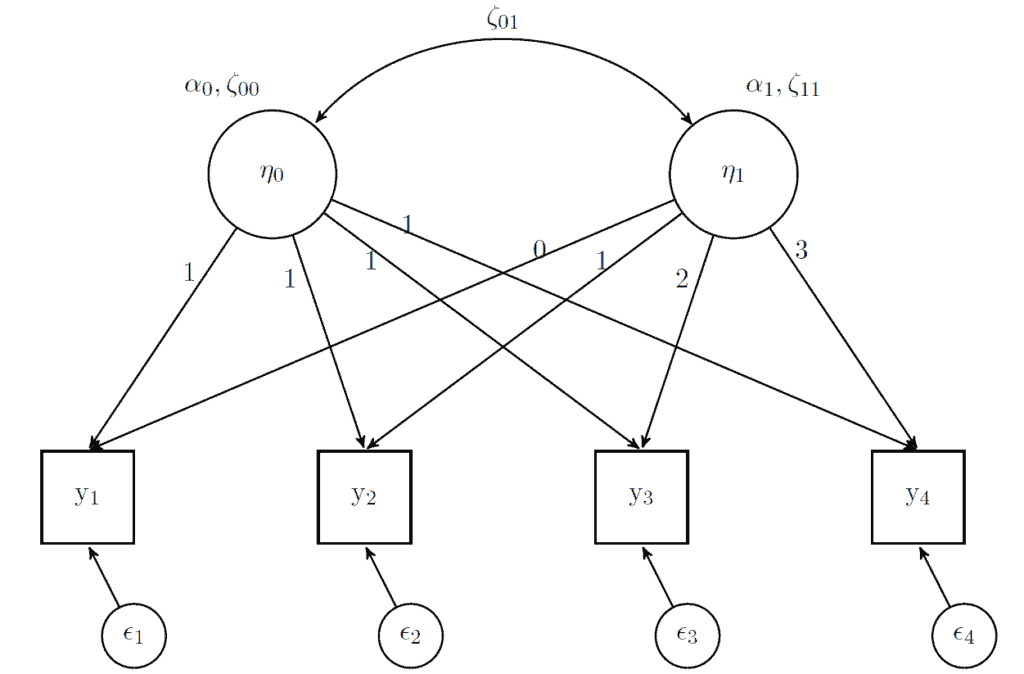
In this framework, latent variables are represented by circles (the two η variables) while observed variables are represented by squares (the four y variables). We also get the residuals (small circles representing ϵ). For the latent variables, we have averages (α) and variances (ζ). These are estimated and have the interpretation described before. The arrows between the latent and observed variables (which are just regression slopes or loadings) are fixed in advance. For the intercept latent variable (represented by η0) the loadings are fixed to 1 (that is why there is nothing multiplied with α0 and ζ00 in the formula above). The loadings for the slope latent variable (represented by η1) are fixed according to the change in time (λj in the formula above). In this case it simply goes from 0 to 3. We also correlate the starting point and the change in time, represented by the double arrow ζ01. This is not often interpreted but it basically gives you an idea that people are converging (or become more similar in time) or diverging (becoming more different).
Now with the technical part out of the way, we can do some modelling and more graphs!
How to estimate Latent Growth Models in R?
Now we will apply the model above. Here I split the process in three parts: writing the syntax for the model and saving it as an object, running the model using the growth() command and look at the summary.
We use logincome measured at six points in time (“logincome_1” to “logincome_6”). We estimate two latent variables, “i” representing the intercept and “s” representing the slope, using the =~ command. To run the model we also fix the loadings in advance (as seen in the figure before) to “1” for the intercept and as time (0 to 5) for the slope.
# first LGM
model <- 'i =~ 1*logincome_1 + 1*logincome_2 + 1*logincome_3 +
1*logincome_4 + 1*logincome_5 + 1*logincome_6
s =~ 0*logincome_1 + 1*logincome_2 + 2*logincome_3 +
3*logincome_4 + 4*logincome_5 + 5*logincome_6'
fit1 <- growth(model, data = usw)
summary(fit1, standardized = TRUE)
## lavaan 0.6-8 ended normally after 45 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 11
##
## Number of observations 8752
##
## Model Test User Model:
##
## Test statistic 523.408
## Degrees of freedom 16
## P-value (Chi-square) 0.000
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## i =~
## logincome_1 1.000 0.827 0.842
## logincome_2 1.000 0.827 0.923
## logincome_3 1.000 0.827 0.949
## logincome_4 1.000 0.827 0.977
## logincome_5 1.000 0.827 0.993
## logincome_6 1.000 0.827 0.949
## s =~
## logincome_1 0.000 0.000 0.000
## logincome_2 1.000 0.115 0.128
## logincome_3 2.000 0.229 0.263
## logincome_4 3.000 0.344 0.406
## logincome_5 4.000 0.459 0.551
## logincome_6 5.000 0.574 0.658
##
## Covariances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## i ~~
## s -0.047 0.002 -25.789 0.000 -0.497 -0.497
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .logincome_1 0.000 0.000 0.000
## .logincome_2 0.000 0.000 0.000
## .logincome_3 0.000 0.000 0.000
## .logincome_4 0.000 0.000 0.000
## .logincome_5 0.000 0.000 0.000
## .logincome_6 0.000 0.000 0.000
## i 7.063 0.010 734.511 0.000 8.538 8.538
## s 0.041 0.002 23.527 0.000 0.354 0.354
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .logincome_1 0.280 0.006 45.748 0.000 0.280 0.291
## .logincome_2 0.201 0.004 48.502 0.000 0.201 0.250
## .logincome_3 0.212 0.004 54.736 0.000 0.212 0.279
## .logincome_4 0.197 0.004 54.733 0.000 0.197 0.275
## .logincome_5 0.176 0.004 49.002 0.000 0.176 0.254
## .logincome_6 0.217 0.005 43.584 0.000 0.217 0.286
## i 0.684 0.012 55.548 0.000 1.000 1.000
## s 0.013 0.000 31.248 0.000 1.000 1.000There are six types of coefficients that are interesting here:
- intercept i: the value 7.063 represents the average expected logincome at the start of the study for all the respondents.
- intercept s: the value 0.041 represents the average rate of change for all the respondents. So with each wave log income goes up by 0.041.
- variance i: the value 0.684 represents the between variation at the start of the study. So how different are people compared to the average.
- variance s: the value 0.013 represents the between variation in the rate of change. It shows how different are change slopes for different people.
- variance logincome: the values ranging from 0.176 to 0.280 represent the within variation at each point in time.
- correlation between i and s: the value -0.497 highlights that people’s income converges in time.
How to visualize change?
A good way to understand what you are modelling is to visualize the predicted scores from your model. We will use the predict() command to save a new object with the individual-level predicted scores for the intercept and slope.
# predict the two latent variables pred_lgm <- predict(fit1)
This has the predicted score for the intercept and slope for each individual:
head(pred_lgm) ## i s ## [1,] 7.098045 0.02427041 ## [2,] 7.032071 0.02067198 ## [3,] 7.076023 0.05292766 ## [4,] 7.473100 0.02528456 ## [5,] 7.175915 0.09630486 ## [6,] 7.373751 -0.22024325
These are based on our model. So, for example, we could estimate the mean of these variables and it should give us the same results as above:
# average of the intercepts (first column) mean(pred_lgm[, 1]) ## [1] 7.062587 # average of the slope (second column) mean(pred_lgm[, 2]) ## [1] 0.04066347
To plot the results we want to transform this data (intercept (η0) and slope (η1)) into expected scores at each wave (yj). We can do this transformation based on the path model we have seen in above:
yj = η0 + η1λj
So, for the first wave the expected value is just the intercept (η0) because λj is equal to 0. For the second wave, the expected value would be the intercept (η0), slope (η1). For wave three it would be intercept + 2 * slope, and so on.
In R we could calculate all these waves by hand or we could do it automatically using a loop or functional programming. Based on the formula above we can create a counterpart in R:
pred_lgm[, 1] + x * pred_lgm[, 2]
where x represents our coding of time (or λj). We can apply this function multiple times using the map() command. The syntax below applies this formula for the numbers 0, 1, 2, 3, 4, 5 (our coding of time).
map(0:5, # what to loop over, in this case numbers 0 to 5
function(x) pred_lgm[, 1] + x * pred_lgm[, 2]) # formula to useAll of this hopefully should give you an intuition how the latent variables translate in expected values in our original data. Below I build on this formula and make a long dataset that has the predicted scores for the individuals at different waves. We can then use this to do nice plots using ggplot2.
A good way to understand syntax is to run it in stages. So you could first just run the map() command, then map() and reduce() together and so on, to understand what each step does.
# create long data for each individual
pred_lgm_long <- map(0:5, # loop over time
function(x) pred_lgm[, 1] + x * pred_lgm[, 2]) %>%
reduce(cbind) %>% # bring together the wave predictions
as.data.frame() %>% # make data frame
setNames(str_c("Wave", 1:6)) %>% # give names to variables
mutate(id = row_number()) %>% # make unique id
gather(-id, key = wave, value = pred) # make long format
# make graph
pred_lgm_long %>%
ggplot(aes(wave, pred, group = id)) + # what variables to plot?
geom_line(alpha = 0.01) + # add a transparent line for each person
stat_summary( # add average line
aes(group = 1),
fun = mean,
geom = "line",
size = 1.5,
color = "red"
) +
theme_bw() + # makes graph look nicer
labs(y = "logincome", # labels
x = "Wave")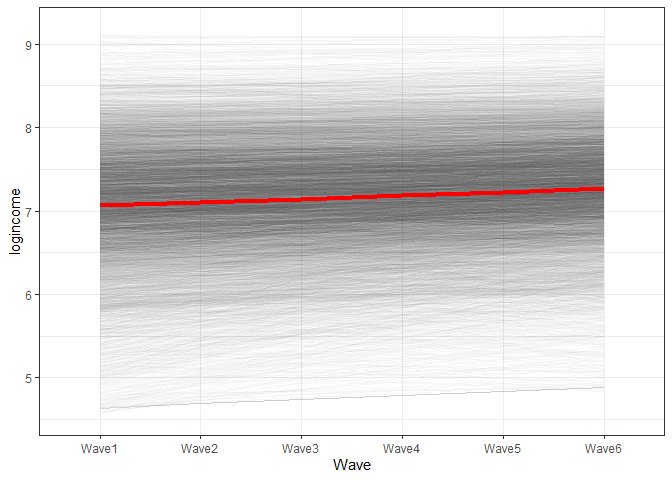
So this is the predicted change in time based on our model. We see that th red line represents the average intercept and slope as shown in the LGM. We also see that each individual has different starting points and rates of change and this diversity is captured in the variance components of LGM.
Conclusions
Hopefully, that gives you an idea about what is LGM, how to estimate it in R and how to visualize change using it. If you liked this you can check the follow-up post that shows how to estimate non-linear change using LGM or see how this model compares to the multilevel model for change. You can also learn how to include time-constant and time-varying predictors in LGM models here and here and how to run parallel LGM here. Also, this post looking at visualizing transition in time for categorical variables might be of interest.
If you have questions feel free to post them in the comments below.
Was the information useful?
Consider supporting the site: